Русификация ASTLIBRA: Разгадка тайных текстов!
Привет всем! Сегодня мы продолжаем наше приключение по русификации ASTLIBRA. В прошлый раз мы разобрались с форматом файла и начали извлекать тексты. Но, как оказалось, все не так просто!
Но перед этим немного про сбор на перевод игры.
Сбор на перевод помогает:
Покрыть часть расходов на работу. Все хотят есть, а работа над этой игрой требует много времени и сил.
Повысить мотивацию, ведь вкладываем свою душу в проект.
Перевод будет, несмотря на сборы, если даже не соберёт нужную сумму.
Загадочные указатели:
Первая проблема – это странное расположение указателей на текст. Они не были упорядочены, как мы ожидали, а как будто разбросаны хаотично. Пришлось разбираться с этим "беспорядком" и создавать специальный инструмент для извлечения текста.
Дискотека в hex-редакторе:
Мы разработали специальный шаблон для hex-редактора, чтобы лучше разобраться в структуре файла. Вид этого шаблона напоминал дискотеку – множество цветов и элементов, которые нужно было разгадать. После долгих размышлений, мы, наконец, смогли понять, как работает этот файл.
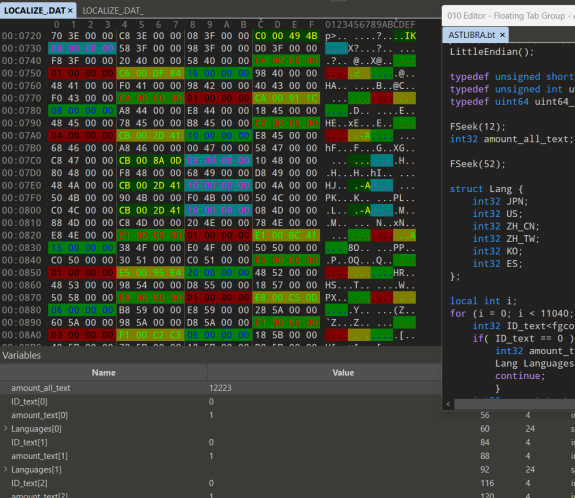
Программа-спасатель:
С помощью разработанного шаблона мы написали программу, которая позволяет извлекать текст и затем упаковывать его обратно в файл. Из-за непредсказуемого порядка указателей, пришлось добавить множество дополнительных условий в программу.
Первая проблема:
И вот, мы получили текст, но при попытке его внедрить в игру – ничего! Лишь несколько слов отображались, а остальные были заменены на сообщение "нет локализации". Оказалось, что разработчики игры решили использовать уникальные идентификаторы (ID) для каждого текста, которые нельзя менять местами в файле т.е. нельзя писать например: ID:3 ID:1, ID:16. ID всегда должен идти по порядку.
Новые сложности:
Мы вернули ID на свои места, но проблема не исчезла. Некоторый текст отображался, а некоторые – нет. Пришлось снова разбираться и, наконец, выяснилось, что после каждого текста нужно добавить 8 байт с нулями! И не просто нулями, а с учетом того, сколько байт занимает текст: если текст заканчивается на 1 байт, то нужно добавить 7 нулей, и так далее. Но есть еще пару нюансов как на картинке.
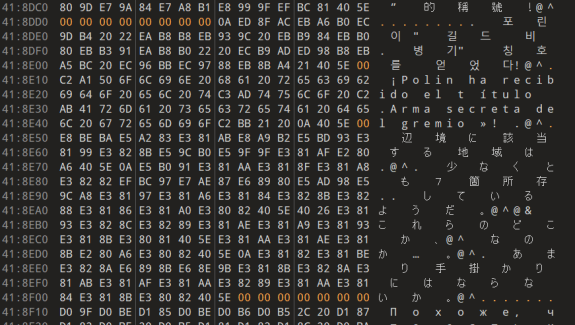
Тексты в хаосе:
Справившись с этой проблемой, мы приступили к переводу. Но снова нас ждал сюрприз: текст был не по порядку, а хаотично перемешан!
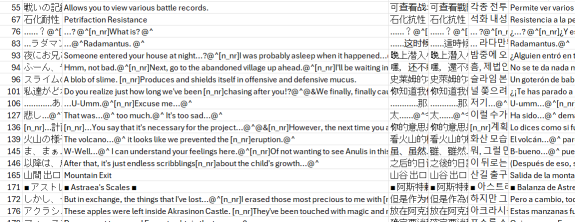
Из-за этого процесс перевода стал очень сложным, ведь нужно было внимательно следить за соответствием текста и ID.
Спасение – в сортировке:
Мы решили создать таблицу, где будем хранить оффсеты текста, а затем отсортировать ее по возрастанию. Теперь, наконец, у нас есть упорядоченный текст, готовый для перевода!

Эксель подвел:
Конечно, без препятствий не обошлось. Эксель, который мы использовали для сортировки, не предусматривал обратной функции, чтобы вернуть текст на нужную строку. Но это уже другая проблема, которую мы решили.
Первый шаг к русификации:
Несмотря на все трудности, нам удалось сделать первый шаг к русификации ASTLIBRA. Переведено несколько фрагментов, и результат уже виден!
Продолжение следует...
Это была лишь часть нашей истории. Впереди еще много работы и новых испытаний, но мы не сдаемся! Следите за обновлениями, и вы узнаете о новых достижениях в русификации ASTLIBRA.
astlibra
русификатор
разбор
СакритиС
Блин,а мне нравится этот ежедневный дневник переводчиков )) Огромное Вам спасибо
Nov 09 2024 08:58 
1
sonic boy
это очень увлекательно читать даже.
Nov 11 2024 23:51


