Делаю игрулю на Playdate на чистом C. Глава 1
Не так давно (год назад на самом деле) я приобрёл необычную игровую консоль Playdate.

Она такая маленькая, жёлтая и имеет крутилку (крэнк или иногда в дословном переводе с испанского кривошип). Ах да, у неё еще экран монохромный. Не чёрно-белый - чёрно-белый экран умеет показывать оттенки серого
gif
170606843517678015.gif1.99 Mb
- монохромный умеет показывать только чёрное и белое. Точнее, не совсем белое, а что-то что не чёрное.
Playdate это неповторимая смесь примитивизма и современных технологий. На первый взгляд можно подумать «ну и кто в такое играет?». Однако я щас без преувеличений скажу, что уже для Playdate сделано более 800 игр. То есть, в отличие от миллиона неизвестных консолей, которые сегодня создаются для тех, кто вспоминает детство за сегой и дэнди, пардон, нинтендой, у Playdate реально есть активное сообщество.
Какую игру я хотел сделать? Примитивные головоломки я отбросил сразу же. Хотелось сделать что-то драйвовое, чтобы прям был экшон как в GTA - машины там, физика, стрельба. Значит, нам нужна машина! Понятное дело, игра будет двухмерная. Если машина, значит, она должна ездить, и желательно не с идиотским видом сверху как в GTA2 (справедливости ради уточню, что я прошёл всю GTA2, и посмотреть это можно на ютубчике), а чтобы была перспектива, чтобы было красиво. Так как никакого 3D не ожидается, а для управления у нас есть крестовина (D-Pad на английском). Значит, нам нужна машинка в восьми направлениях. Дав задачу своей художнице я получил вот такое:
"Так, стоп, а какой сеттинг у игрули?" спросишь ты. Сеттинг простой - мы катаемся на внедорожнике вооружённым пулемётом по пустыни в Австралии и, как настоящие любители дикой природы, отстреливаем живность: эму и кенгуру. Справедливости ради уточню, что живность нас тоже пытается грохнуть. То есть, жанр игры "выживальщик" наподобие Vampire Survivors.
Так как у Playdate только два цвета, нам нужно постараться чтобы создать ощущение нахожения в пустыне. Потому сначала сконцентрируемся на реквизите, который нас будет окружать. Конечно же это кактусы, небольшие песчаные насыпи и перекати-поле.
Ах-да, забыл упомянуть: размер экрана у нас 400 на 240 пикселей. То есть, ну очень маленький. Значит, объектов на экране должно быть минимум чтобы понять что происходит.
Перейдём к самому вкусному - к коду.
На Playdate официально можно разрабатывать на двух языках программирования: C и Lua. Так как Lua я не переношу как и все скриптовые языки (я лично за С++ во всех нормальных играх), значит будет сишка. Не сказать, что я фанат сишки, но это лучше луы. А что делать с отсутствием объектно ориентированного программирования? Будем симулировать и выкручиваться по возможности, потому что 10 лет работы на ООП языках (Swift, C++, C#) чётко отформатировали мою голову под объектно-ориентированное мышление.
Первый шаг в написании игры это файл main.c, в котором нет функции int main, зато есть системный колбэк ("обратный вызов" или "звони назад")
int eventHandler(PlaydateAPI* playdate, PDSystemEvent event, uint32_t arg).
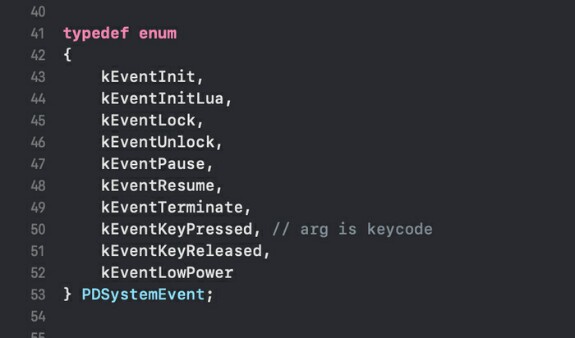
Эта функция это единственная прослойка между Playdate и моим кодом. Она вызывается на любой "чих", точнее, событие. Первый аргумент PlaydateAPI* playdate это указатель на непосредственно API операционной системы девайса. PlaydateAPI это структура, которая состоит из структур, которые хранят сишные указатели на большое количество функций (нарисовать, что-то, открыть файл, показать fps и т.д.). Второй аргумент это наш тип "чиха", точнее, события:
На третий аргумент arg пока пофиг - он нам не нужен.
Код игры можно воткнуть прям в файл main.c, но я так не хочу. Не потому что это считается зашкварно - то что как считается это вещи очень субъективные, и вряд ли они когда-то меня останавливали от самых сумасшедших вещей в коде. Я вынесу код отдельно потому что я хочу чтобы он был распределён красиво и удобно, модульно, но не слишком. То есть, чтобы лично мне было понятно где что искать, но чтобы не упарываться в оформление структуры ради оформления структуры как это делают Java-разработчики. Потому вся логика катания машины по пустыне будет аккуратно сложена в файл с супербанальным названием Game.
Game будет имитировать класс, он будет создан при получении события о старте игры, и будет удаляться в событии об окончании игры. А указатель на этот объект будет храниться где? Правильно: в статичной памяти.
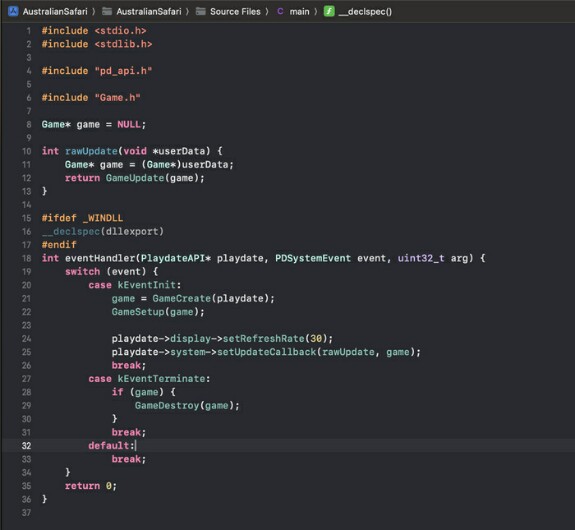
То есть, игра создаётся в событии `Init` (строка 21), потом вызывается у игры функция GameSetup(строка 22) для единоразовых стартовых действий опосля создания (тут можно поспорить, что эти вещи можно сделать в той же функции GameCreate, но спор оставим тем, кто любит спорить вместо написания кода). Далее я прикручиваю вызов функции GameUpdate к тику игры. Напрямую я это сделать не могу так как функция обновления имеет сигнатуру int (*)(void *), а мне нужно int (*)(Game *), потому я создаю функцию-прослойку rawUpdate, которая принимает void *userData, кастит его в указатель на Game и руками вызывает GameUpdate.
Отлично, с мэйном всё понятно. Теперь давай глянем что есть в самом Game. Но сначала позволь проспойлерить и показать что получилось чтобы ты не зевал от кода.
Откатимся назад в прошлое. Сишка кажется нормальным языком, но ровно до того момента, когда тебе нужно работать с динамическими объектами: строками и массивами. Оказывается, что чтобы передать массив в функцию нужно иметь два аргумента: указатель на данные и целое число равное количеству объектов, лежащих по тому самому указателю один за другим в памяти как поезд. Ну либо можно хранить объекты в статичной памяти, там всё проще - объявил статичный массив и пользуйся. Одно но - у статичного массива константный размер, и этот размер должен быть известен в момент компиляции. Чем это чревато? Тем, что если ты объявил массив, скажем, кактусов, размером, скажем, 100 штук, это значит, что в игре 101 и более кактус быть уже не может. И так с любым статичным массивом.
Забавный факт: когда несколько лет назад слили исходники GTA3 и GTA Vice City там динамические объекты (машины, пешеходы, пикапы (броня, спрятанные пакеты, буйства, оружия, деньги)) как раз хранились в статичных массивах. И количество пикапов, например, ограничивалось числом 512. То есть, если в игре устроить заварушку чтобы вокруг валялось много денег, оружия и прочих пикапов в количестве 512, то при появлении нового один старый пикап тут же будет пропадать даже если ему ещё рано пропадать (деньги и выпавшее из врагов оружие пропадают по таймауту).
Вот я так не хочу. А хочу я чтобы у меня был один объект массива без отдельно указателя на данные и отдельно размера, потому что если таскать везде два аргумента представляя что это один, это верный способ свихнуться. А если мне нужно два массива - будет два объекта. А все детали (указатель на данные, размер, прочее) должны быть аккуратно спрятаны внутри, как это сделано в ООП языках. В С++ для таких целей есть std::vector, в Swift - Array, в C# - List. В сишке ничего такого нет, значит надо придумать!
Долго томить не буду, вот что получилось:
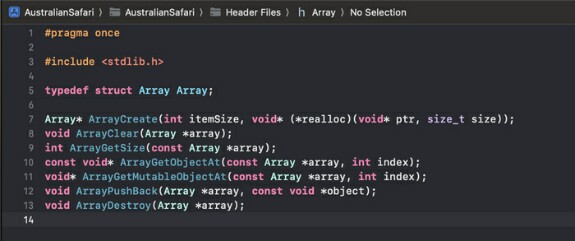
Заголовочный файл имеет предобъявление структуры Array, которой по факту не существует, и API для создания, взаимодействия и уничтожения массива. Важная деталь: так как это сишка у нас нет деструкторов как в С++/C# или deinit-функций как в Свифте, которые автоматически вызываются когда область видимости массива заканчивается. Значит, нам надо вызывать функцию-деструктор руками. То есть, на каждый вызов ArrayCreate где-то должен быть один вызов ArrayDestroy. А что будет если забыть вызвать ArrayDestroy? Правильно: утечка памяти. Я чувствую себя программистом-дауншифтером. Но я сам так решил: начал танцевать с дьяволом - жди окончание песни.
Теперь давай я покажу тебе реализацию:
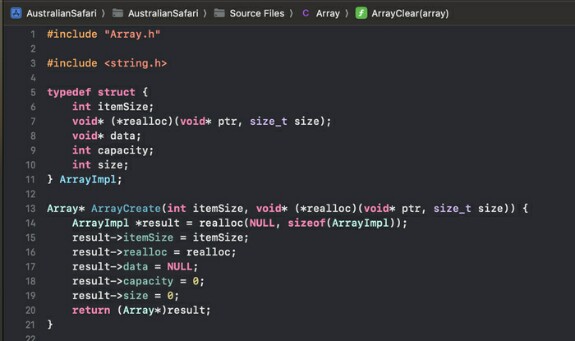
Тут у нас есть структура ArrayImpl. И мы в функции ArrayCreate создаём именно инстанс структуры ArrayImpl, а не Array (та самая несуществующая структура), однако указатель на созданные данные нагло кастим в указатель на Array. Зачем так делать? Честно скажу, я это подглядел у команды SQLite в исходном коде SQLite. Таким образом мы разделяем интерфейс и прячем реализацию, то есть, делаем её приватной в языке программирования, где приватности нет (я про слово private говорю, которое есть чуть ли не в каждом известном мной объектно-ориентированном языке программирование, за исключением Свифта самой первой версии - там уровни доступа не сразу завезли). Логика в том, что весь API массива принимает указатель на Array, а внутри этот указатель кастуется в указатель на ArrayImpl, который хранит реальные данные нашего массива.
А, кстати, что же хранит ArrayImpl? На последнем скриншоте мы видим, что там не два поля как это бывает у сишного массива, а больше:
1) int itemSize - это размер одного хранимого объекта в байтах. Этот размер нужен чтобы знать сколько байт выделять когда мы пытаемся засунуть в массив один объект (push_back в векторе на C++, append в Свифте у массива и Add в C# у листа). Ты возразишь "но ведь С++ вектор не хранит это поле, значит можно в нашем случае тоже как-то его избежать!". Однако, С++ на самом деле хранит это поле, просто не в виде явного члена класса, а в качестве параметра шаблона: std::vector<T> имеет параметр шаблона T, от которого в любой функции внутри класса std::vectorможно вызвать sizeof(T) и получить заветный размер одного объекта. Однако в сишке шаблонов нет. Вот прям совсем нет. Примерно как нет воздуха на Луне. Потому приходится передавать один дополнительный параметр int itemSize, который позволит нам во время жизни массива знать размер одного элемента. Нет, конечно в сишке есть макросы, которые при достаточной сноровке можно использовать как шаблоны, однако я имею аллергию на макросы, так что макросов не будет.
2) Указатель на функцию realloc. Это может выглядеть избыточно, и по факту так оно и есть, однако у PlaydateAPI (помнишь, я тебе в файле main.c показывал указатель на такую структуру?) есть свой указатель на функцию realloc, который, как мне подсказывает мой копчик, равен системному вызову realloc из стандартной библиотеки Си, и который можно вызвать вот так playdateApi->system->realloc. То есть, нам разработчики намекают использовать их realloc вместо системного. Что ж, это нетрудно. А вторая причина - передача функции realloc по указателю позволяет покрыть вызовы этой функции юнит-тестами, то есть, сделать мок или прокси этой функции, и это невероятно удобно. Правда, я до сих пор не покрыл массив юнит-тестами, но когда-нибудь я обязательно это сделаю, честно-честно!
3) void *data это непосредственно указатель на данные. Почему именно указатель на void? Потому что массив по своей природе универсален: он способен хранить и int'ы, и кастомные структуры, а значит нужен указатель какого-то общего типа, что-то вроде object в C# или AnyObject в Свифте. И тут сишка нам щедро предлагает указатель в пустоту. Любой сишный прогер знает, что указатель на void это произвольные данные. В нашем случае это данные массива. Массив может хранить N объектов, а значит в этом состоянии у него указатель dataбудет указывать на кусок памяти в минимум N * itemSize байт идущих подряд если только N не равен 0. А если массив пустой, то data равен NULL.
4) int capacity это ёмкость данных. Ёмкость равняется количеству объектов, которые умещаются в объём выделенных данных, которые лежат по адресу data.
5) int size это количество реальных объектов, которые лежат по адресу data. "В чём отличие sizeот capacity?" спросишь ты. Тут логика та же, что и у std::vector в C++ - capacity в некоторых случаях может отличаться от size. Например, если в массиве было 4 объекта, и мы один объект удалили чтобы осталось 3, мы не будет выделять новый участок памяти под 3 элемента, а старый освобождать. Мы просто уменьшим size, но оставим capacity как есть. Это, во-первых, быстрее, чем перераспределять память (особенно если в массиве лежит больше тысячи объектов), во-вторых, если после удаления мы решим снова добавить объект, то память вновь не придётся перераспределять, так как ёмкости массива хватит. Да. безусловно если помимо этого одного мы добавим ещё один, то придётся осуществить перераспределение чтобы выделить больший кусок памяти, но тут мы уже ничего сделать не сможем, кроме как заранее оптимизировать пытаясь предсказать какая ёмкость лучше. Но это уже не ответственность массива - это ответственность того, кто этим массивом пользуется.
Итого я расписал как устроена внутрянка массива. Не будем забывать мою цель - мне нужен аналог std::vector из С++ или Array из Свифта удобный настолько, насколько это возможно в сишке. Так что давай я покажу как устроен API у массива.
1) ArrayCreate (на прошлом скриншоте есть) - эта функция создаёт объект массива. Она принимает itemSize и указатель на функцию realloc. Задача функции - выделить память под ArrayImpl, присвоить все стартовые поля ему и вернуть созданный указатель, но в качестве Array*, а не ArrayImpl*. Количество объектов у только что созданного массива всегда равно нулю. Возможности создавать массив из литерала как в С++ (auto myArray = {1, 2, 3}), C# (var myArray = new int[]{ 1, 2, 3 }), Swift (let myArray = [1, 2, 3]) и даже Objective-C (NSArray *myArray = @[@1, @2, @3]) нет, так как это просто синтаксический сахар над несколькими операциями (создание и заполнение), и негоже такое в сишке иметь.
2) ArrayClear - функция очистки массива.
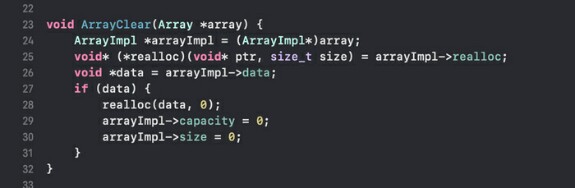
Это не уничтожения массива, а именно опустошение хранилища если количество хранящихся объектов в массиве больше нуля. Название я полностью взял с std::vector::clear из С++. Можно было взять removeAll из Свифта, но к clear я больше привык. Суть функции: мы берём полученный аргумент и кастуем его в указатель на ArrayImpl. Если data у полученного объекта не равна нулю, т.е. если массив непустой, то мы дропаем дату и запоминаем, что capacity и size равны нулю. Ну а если массив и так пустой, то мы не производим никаких операций с памятью.
3) ArrayGetSize - самая простая функция, которая возвращает размер массива.

Просто кастуем указатель и возвращаем хранящееся значение size.
4) ArrayGetObjectAt - получение объекта. В "нормальных" языках у нас есть оператор "квадратные скобки", а тут у нас сишка, так что любое действие это просто функция.
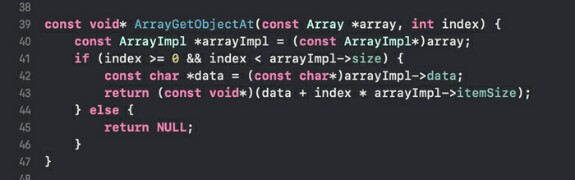
Функция возвращает адрес, то есть, указатель на нужный объект по указанному индексу в массиве. Так как храниться может внутри что угодно, то возвращаем мы уже известный нам указатель на void. А задача клиента будет уже скастовать этот указатель в указатель правильного типа: если в массиве лежат int'ы, то надо будет скастовать в int, если float - то во float, если кастомная структура или union - ну ты понел. И тут, понятное дело, можно легко спутать тип потому что мы люди, а люди ошибаются. Как страхуются от таких проблем в других языках? В С++ всё так же шаблонами: если std::vector<T> имеет T равный int, то и operator[] будет возвращать T и только T. В Свифте то же самое, только там не шаблоны, а дженерики - шаблоны на минималках, в C# тоже дженерики. А в сишке мы дауншифтим, смирись с этим и не выпендривайся! Ах да, если индекс переданный в функцию оказался за пределами доступных объектов (меньше нуля или больше либо равен размеру массива), то мы просто вернём нулевой указатель. В троице моих упомянутых выше языков в этом случае бросается исключение, но в сишке исключений нет, да и как по мне без исключений код приятнее, потому что исключения это тот же оператор goto, от которого нас так яростно отучивали 20 лет назад. Потому мы возвращаем NULL. А если индекс валиден, то мы хитрой арифметикой указателей вычисляем правильный адрес и возвращаем его.
5) ArrayGetMutableObjectAt - это копия прошлой функции, но возвращающая неконстантный указатель на объект. Почему это важно выделить в отдельную функцию?
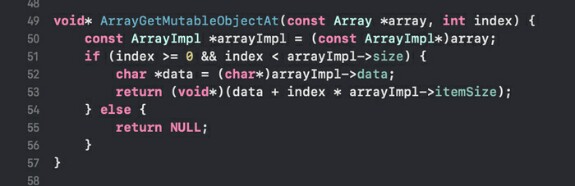
Язык у нас, конечно, не самого высокого уровня, однако константность в нём есть полноценная, а константность это штука, которая невероятно повышает читаемость кода (я особенно привык объявлять константы вместо переменных во время работы на Свифте, а потом когда в плюсовом проекте везде втыкаю const иногда встречаю возмущенные ревью "ну и нахуа ты везде свой бесполезный const понапихал 🗿"), однако константы почему-то максимально игнорируются программистами на сишке, что я лично не одобряю никак.
6) ArrayPushBack - добавление объекта в массив. Аналог std::vector::push_back из C++, Array.appendиз Свифта и List.Add их C#.
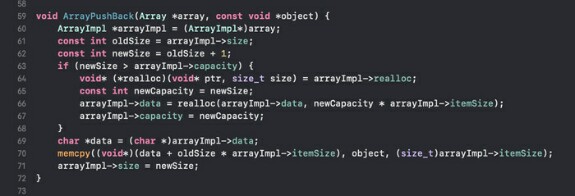
Это самая навороченная по логике функция массива. Объект передаёт константным указателем на void. Тут нам сначала нужно проверить умещается ли новый объект в уже имеющуюся ёмкость (capacity). Если умещается, то мы просто копируем его в data со сдвигом равным старому размеру помноженному на размер объекта (itemSize), а количество байт для копирования тоже равны размеру объекта (itemSize). Важно при вызове ArrayPushBack передавать адрес объекта, а не сам объект, а то будет ошибка: ArrayPushBack(myArray, &myValue). Неудобно, согласен, зато универсально, потому что в таком массиве можно хранить и структуры, и базовые типы.
7) ArrayDestroy - последняя на сегодня функция массива. Эта функция, как ты уже знаешь, уничтожает массив, то есть чистит его из памяти. Любой массив рано или поздно окажется тут, где закончится его путешествие по этому бренной жизни, точнее, по материнской плате. Эта функция это Вальгалла всех массивов. В неё мечтает попасть каждый массив, а те, кто не попадают, те остаются болтаться в утекшей памяти.
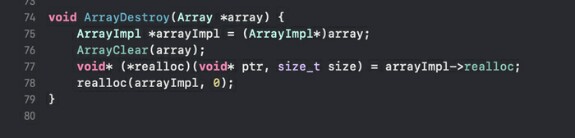
Тело функции крайне банально: сначала вызываем ArrayClear чтобы почистить объекты если они есть, а далее дропаем массив из памяти словно он никогда и не существовал.
Заключение
Признаюсь, стилистику имитации объектов я взял в CoreFoundation - это такая сишная либа от Эпла, которая имеет API очень похожий на Objective-C, на основе которого позже появился Swift. Это, кстати, не единственный способ имитации ООП в сишке - ещё я пользовался либой GTK+, но там API немного отличается, в частности, там всё обмазано макросами, а на них у меня аллергия.
PyXiion
Круто!
Jun 14 2024 21:31 
1