Все о моделях FLUX, GGUF, квантизации, чем они отличаются и какую выбрать для своей видео-карты

Всем привет))
Если вы читаете этот пост, то скорее всего у вас тоже куча вопросов к этим моделям, которые так неожиданно ворвались в наш уютный нейро мир. А ведь так все просто и понятно до этого было, были модели 1.5 и XL, для каждой было по одному вае и на этом в принципе все, что нужно было для генераций (хотя даже и в этом кто то умудрялся запутаться). А теперь? Fp8, nf4, GGUF со своей квантизацией, да еще клипы, энкодеры... Как говорил один мудрый человек - сам черт ногу сломит.
Но на самом деле все не так уж и страшно, если разложить все по полочкам, а я постараюсь вам в этом помочь)) Ну что, начнем с простого?
Кратко о самой модели FLUX
Кратко о самой модели FLUX
FLUX - это передовая модель для создания изображений, которая генерирует невероятно реалистичные и детализированные картинки.
Основные особенности FLUX:
- Созданные изображения выглядят почти как настоящие фотографии.
- В основе FLUX лежат современные методы обработки данных и искусственного интеллекта.
- Система использует сложные алгоритмы для анализа и создания изображений.
- Она "изучила" миллионы изображений, чтобы научиться создавать свои.
- FLUX превосходит многие существующие модели по качеству и реализму деталей.
- Она может создавать изображения, которые трудно отличить от настоящих.
- FLUX имеет сложную многоуровневую структуру. Каждый уровень отвечает за определенные аспекты изображения: цвета, формы, текстуры и т.д.
- Когда вы просите FLUX создать изображение, все части модели работают вместе. Это позволяет создавать высококачественный и реалистичный результат.
В целом, FLUX - это мощная модель для создания изображений, которая может воплотить в жизнь практически любую визуальную идею с высокой степенью реализма.
Версии модели FLUX
На сегодняшний день существуют три официальны версии модели FLUX:
- Schnell (что на немецком означает "быстрый"):
Упрощенная версия, требует меньше шагов для выполнения задач, идеальна для быстрых результатов.
- Dev (вероятно, от "Development" - разработка):
Полная модель, обеспечивает более детализированные результаты, подходит для задач, требующих высокой точности.
(Если заглянете в фильтры на Civitai.com то там они будут указаны как: Flux .1 D и Flux .1 S).
- Pro (профессиональная): Оптимизирована для профессионального использования, предлагает наивысшее качество и производительность, требует мощных видеокарт с большим количеством памяти, предназначена для коммерческого использования и для обычных пользователей пока не доступна.
Гибридные варианты: Сочетают особенности обеих моделей, позволяют достичь качества Dev с эффективностью Schnell. Пример:
Гибридные варианты: Сочетают особенности обеих моделей, позволяют достичь качества Dev с эффективностью Schnell. Пример:
BNB nf4, fp8 и shnell, обзор поддерживаемых контрольных точек:
- Оптимизированы для GPU с 6-12 ГБ памяти;
- Использует формат NF4;
- Включают текстовый преобразователь T5xxl_fp8_e4m3fn, языковую модель CLIP-L в fp16 и VAE в bf16;
- Поддерживает "Distilled CFG Guidance" (ползунок в Forge) с настройками 3,5;
- Оптимизированы для GPU с 6-12 ГБ памяти;
- Не рекомендуется использовать отрицательные подсказки.
BNB-NF4 - это самый "легкий" формат из упомянутых, где:
- "bnb" в названии модели прямо указывает на использование Bitsandbytes - библиотека, которая позволяет выполнять квантизацию модели, то есть уменьшать точность представления весов нейронной сети с целью оптимизации использования памяти.
- "nf4" означает 4-битную квантизацию, что является одной из возможностей BNB, благодаря которой модель генерирует быстрее, и меньше съедает памяти
В отличии от первой версии версия flux1-dev-bnb-nf4-v2 была оптимизирована для устранения необходимости в дополнительном этапе квантования. Она занимает на 0,5 ГБ больше места по сравнению с предыдущей версией, потому что теперь использует формат float32 для хранения данных с полной точностью. Это улучшает точность модели по сравнению с предыдущей версией. Версия v2 не требует второго этапа сжатия, она меньше нагружает систему и немного быстрее выводит результаты.
МИНИМАЛЬНЫЕ ТРЕБОВАНИЯ ДЛЯ МОДЕЛЕЙ:
Для видеокарт с 6-8 ГБ VRAM (RTX 2080 Ti, RTX 3050):
flux1-schnell-bnb-nf4.safetensors. Оптимизирована для быстрой работы на картах с ограниченной памятью.
Для видеокарт с 8-12 ГБ VRAM и выше (RTX 3060, RTX 3070):
flux1-dev-bnb-nf4-v2.safetensors. Баланс между качеством и скоростью, подходит для большинства задач.
Важно!!! Модели NF4 не работают на видеокартах серий 1000 и большинстве карт серии 2000. RTX 2060 Super, 2070 Super, 2080 Super и их Ti версии по некоторым отзывам могут поддерживать NF4 и FLUX, но это не точно, проверяйте, если у вас работают, напишите в комментариях.
Проблема несовместимости LoRA FLUX с моделями BNB NF4
Кто пробовал использовать Lora на моделях nf4 наверное уже заметил, что они не работают, или работают некорректно, эта проблема возникает из-за нескольких факторов:
- Разные форматы квантизации:
LoRA обычно использует fp16 или fp32, BNB NF4 использует 4-битную квантизацию;
- Несовместимость слоев:
LoRA модифицирует определенные слои модели, NF4 квантизация изменяет структуру этих слоев;
- Проблемы с точностью:
NF4 уже сильно сжимает данные. Добавление LoRA может привести к потере критической информации;
- Отсутствие поддержки:
Библиотеки, реализующие LoRA, могут не поддерживать работу с NF4.
Для того что бы лоры заработали на моделях NF4, нужно в интерфейсе в "Diffusion in Low Bits" включить bnbnf4 (fp16 LORA):

2. flux1-schnell-fp8.safetensors - оптимизированная контрольная точка Flux-Schnell в формате FP8:
- Оптимизирована для быстрой генерации изображений;
- Использует 8-битное представление чисел с плавающей точкой;
- Значительно уменьшает требования к памяти по сравнению с FP16;
- Обеспечивает высокую скорость работы при незначительной потере качества.
- Уменьшенное количество параметров, меньше слоев или меньше нейронов в слоях.
Schnell жертвует некоторой долей качества и гибкости ради скорости.
Она может быть менее универсальной, чем полная версия Flux.
3. flux1-dev-fp8.safetensors - полная контрольная точка Flux-dev (уменьшенная версия) в формате FP8:
- 8-битное представление чисел с плавающей точкой;
- Занимает меньше памяти, но имеет меньшую точность;
- Позволяет ускорить вычисления и уменьшить требования к памяти;
- Подходит для задач, где не требуется высокая точность;
МИНИМАЛЬНЫЕ ТРЕБОВАНИЯ ДЛЯ МОДЕЛЕЙ SHNELL И DEV:
NVIDIA GeForce GTX 1660 (6 ГБ VRAM)
NVIDIA GeForce RTX 2060 (6 ГБ VRAM)
Рекомендуемые:
NVIDIA GeForce RTX 3050 (8 ГБ VRAM)
NVIDIA GeForce RTX 3060 (12 ГБ VRAM)
NVIDIA GeForce RTX 2070 (8 ГБ VRAM)
Оптимальные:
NVIDIA GeForce RTX 3070 (8 ГБ VRAM)
NVIDIA GeForce RTX 3080 (10 ГБ VRAM)
NVIDIA GeForce RTX 3090 (24 ГБ VRAM)
Любые карты серии RTX 4000
ДОПОЛНИТЕЛЬНО:
ДОПОЛНИТЕЛЬНО:
Для этих моделей необходимо установить текстовые преобразователи T5 (Text-To-Text Transfer Transformer) -t5xxl_fp8_e4m3fn.safetensors или t5xxl_fp16.safetensors и разместить в верхнем меню вместе с VAE и CLIP, (ссылка на зеркало - VAE, CLIP, t5xxl_fp8_e4m3fn, t5xxl_fp16 )
Путь для VAE (ae) - webui\models\VAE, путь для энкодеров и CLIP -webui\models\text_encoder.
Путь для VAE (ae) - webui\models\VAE, путь для энкодеров и CLIP -webui\models\text_encoder.

Основные отличия между t5xxl_fp16 и t5xl_fp8_e4m3fn:
Формат квантизации:
- fp16: 16-битный формат с плавающей точкой;
- fp8_e4m3fn: 8-битный формат с плавающей точкой, где e4 - 4 бита для экспоненты, m3 - 3 бита для мантиссы, fn - нормализованный формат;
Точность и размер файла:
- fp16 обеспечивает большую точность, но занимает больше места;
- fp8_e4m3fn занимает меньше места, но может иметь немного меньшую точность;
Производительность:
- fp8_e4m3fn может работать быстрее на поддерживающем оборудовании из-за меньшего размера данных;
- fp16 может обеспечивать более стабильные результаты в некоторых сценариях.
Подробнее о моделях которым нужны разные дополнительные штуки, можно наглядно посмотреть на странице Forge WebUi
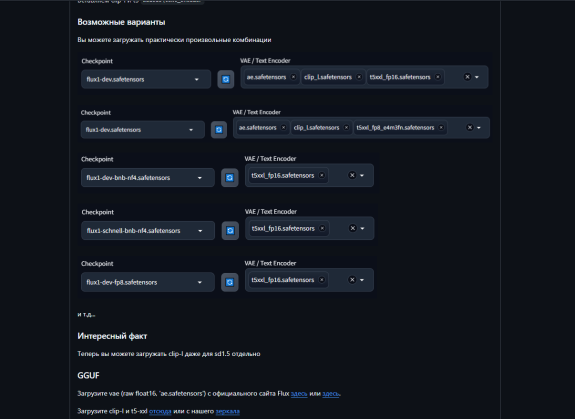
Для nf4 не обязательно добавлять энкодеры как на картинке, но говорят, что с ними модель лучше понимает промпт.
GGUF (GPT-Generated Unified Format)
Дальше мы рассмотрим что такое формат GGUF и с чем его едят)) т.е. основные отличия от FLUX
GGUF (GPT-Generated Unified Format) - это новый формат, пришедший на смену GGML, позволяет более эффективно хранить и использовать крупные языковые модели.
GGUF (GPT-Generated Unified Format) - это новый формат, пришедший на смену GGML, позволяет более эффективно хранить и использовать крупные языковые модели.
А если простым языком, то GUF модели - это те же модели Flux, которые прошли через процесс "упаковки" (квантизации), чтобы стать меньше и эффективнее.
Чтобы понять что такое квантизация, то представьте, что у нас есть большой, тяжелый чемодан (это наша модель Flux). Мы хотим сделать его легче и компактнее для путешествия (то есть для работы в Forge или Comfy). GGUF - это как новый, улучшенный способ упаковки чемодана - более эффективный и универсальный формат, а квантизация - это процесс "сжатия" вещей в чемодане. Мы уменьшаем размер, но стараемся сохранить всё необходимое. В результате мы получаем тот же чемодан (ту же модель), но в более компактном виде. Он занимает меньше места (меньше памяти) и его легче носить (быстрее работает).
Вот основные типы квантизации GGUF, по которым из названия модели вы сможете легко определить, подходит вам модель или нет:
- Q2_K, Q3_K_S/M/L: наименьший размер, высокая скорость, значительная потеря качества;
- Q4_K_S/M: хороший баланс размера и качества;
- Q5_K_S/M: улучшенное качество по сравнению с Q4, незначительное снижение скорости;
- Q6_K: высокое качество, умеренная скорость;
- Q8_0: наивысшее качество, самая низкая скорость.
Рекомендации по выбору GGUF моделей:
если у вас 4-6 ГБ VRAM то подойдут Q3_K_M или Q4_K_S модели
если 8 ГБ VRAM то Q4_K_M или Q5_K_S модели
при 12-16 ГБ VRAM подойдут Q5_K_M или Q6_K модели
а если 24 ГБ VRAM то Q6_K или Q8_0 модели
Совместимость с видеокартами
Модели совместимы с большинством современных видеокарт
работают на картах серий 1000, 2000, 3000 и новее, но я не проверял.
Основные отличия FLUX и GGUF:
Формат:
Flux: "Родной" формат, как оригинальная версия книги;
GUF: "Сжатая" версия, как электронная книга;
Размер:
Flux: Больше, как толстая книга;
GUF: Меньше, как тонкая книжка с тем же содержанием;
Скорость работы:
Flux: Может быть медленнее, особенно на слабых компьютерах;
GUF: Обычно быстрее, особенно на обычных компьютерах;
Точность:
Flux: Максимальная точность, как высококачественная фотография;
GUF: Немного меньше точность, как фото чуть похуже качеством.
ДОПОЛНИТЕЛЬНО:
Для работы GGUF вам понадобятся те же энкодеры, Clip и VAE, что и для обычной модели dev (ссылки выше), без них работать не будет.
На этом у меня пока все, если у вас остались вопросы пожалуйста пишите в комментариях, надеюсь объяснил все понятно и ничего не забыл, и вы теперь точно знаете какие модели выбрать)). Спасибо что дочитали, всем творческих успехов с FLUXом)
Для работы GGUF вам понадобятся те же энкодеры, Clip и VAE, что и для обычной модели dev (ссылки выше), без них работать не будет.
На этом у меня пока все, если у вас остались вопросы пожалуйста пишите в комментариях, надеюсь объяснил все понятно и ничего не забыл, и вы теперь точно знаете какие модели выбрать)). Спасибо что дочитали, всем творческих успехов с FLUXом)

flux





включил "bnbnf4 (fp16 LORA)" как в вашем гайде, но изображения получаются с большим количеством артефактов (пиксельные). Не подскажите почему такое может быть?