Foundation models в геоаналитике
Этот пост вдохновлен Population Dynamics Foundation Model (PDFM), выпущенной Google месяц назад. Для меня это была новая концепция, поэтому показалось интересным разобраться, что такое Foundation Model в контексте пространственного анализа. А так как тема очень актуальная, то решила сделать этот лонгрид доступным для всех)
P.S. по мере изучения модели, стало понятным, что пост получиться скорее познавательным, чем прикладным, поскольку модель Google покрывает только США, но знать, что такое существует все равно, на мой взгляд полезно.
Foundation models
Foundation model - это особенно модный нынче в data science термин, обозначающий универсальные модели, обученные на очень большом количестве данных, которые можно применять к большому набору разных задач. Обычно речь идет о deep leaning моделях. DALL-E и GPT-4 - это примеры foundation models. Их можно использовать как конечные модели для решения отдельных задач: например, распознавания/генерации текста и изображений - в этом случае они управляются промтами (Prompt engineering), так и для создания собственной модели под конкретную задачу. Именно так можно использовать новую модель Google.
То есть вместо того, чтобы с 0 собирать данные и обучать модель, можно только донастроить (fine-tune) существующую модель на небольшом семпле, собранном под конкретный кейс.
Вот ссылка на маркетплейс амазон, чтобы понять какие типы предобученных (pre-trained) моделей существуют
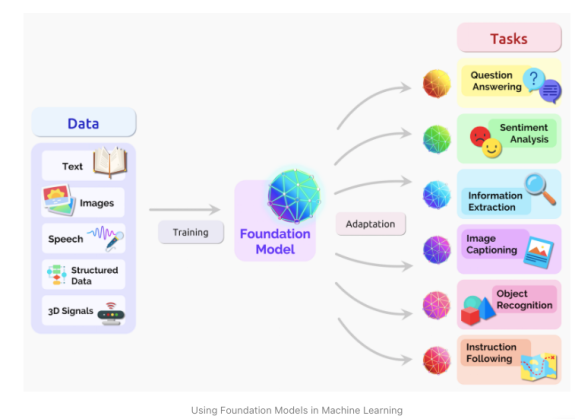
Urban Foundation Models
Модель от Google относится к Urban Foundation Models (UFM)- честно признаюсь, что до появления модели Google, я про них не слышала. Всю информацию ниже я взяла из этой статьи, поэтому за деталями туда:)
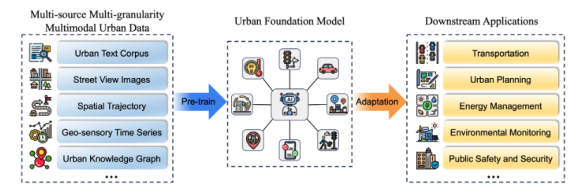
Как можно догадаться, UFM - это foundation models, заточенные под решение городских задач. По описанию выглядит как "универсальная пилюля" для решения всех задач Умного Города.
Основные особенности данных:
Мультимодальность Включает текстовые, визуальные, пространственные и временные данные из городских сред.
Мультиразмерность Данные представлены в разном масштабе, от почтового индекса до страны.
Разнообразие источников
Данные поступают из различных источников, таких как спутниковые снимки, IoT-сенсоры и данные о мобильности.
Другими словами, главное преимущество моделей - огромное число данных из всевозможных источников. По факту всех тех, что упоминаются в классическом описании Smart city - полнота, конечно, будет зависеть от доступности данных для разработчика:
- GPS-траектории
- Камеры видеонаблюдения
- Датчики качества воздуха
- Мобильные данные
- Спутниковые снимки
- Данные переписи
Отсюда большое разнообразие способов применения моделей также огромное: от оптимизации трафика до мониторинга окружающей среды.
Языковые модели:
Что: эти модели анализируют текстовые данные, такие как публикации в социальных сетях, отчеты о пробках или отзывы пользователей
Где: помогают определять настроения, анализировать события или прогнозировать общественные реакции на определенные изменения в городской среде.
Визуальные модели:
Что: обрабатывают визуальную информацию, например со спутниковых снимков или с дорожных камер.
Где: помогают оценивать стоимость недвижимости, выявлять зоны с высокой загруженностью дорог и количественно определять социально-экономическое влияние городов.
Модели траекторий:
Что: Модели, работающие с GPS-данными и траекториями перемещения людей и транспорта.
Где: используются для анализа поведения водителей и пешеходов, прогнозирования следующей локации в маршруте
Модели (пространственно-)временных рядов:
Что: модели, анализирующие данные, которые изменяютсф со временем, например, загруженность дорог, уровни загрязнения воздуха или энергопотребление.
Где: позволяют предсказывать тренды и предупреждать потенциальные проблемы, такие как выбросы CO₂ или перегрузка электрических сетей.
Мультимодальные модели:
Что: интегрируют разные типы данных текстовые, визуальные, пространственные и временные — для более глубокого и комплексного анализа.
Где:объединяют данные о движении транспорта с погодными условиями и социальными данными для прогнозирования городской активности.
Некоторые примеры моделей:
UrbanDiT - модель пространственно-временных рядов, с возможностью применения на весь мир. Ее можно использовать, например, для прогнозирования трафика, толп пешеходов, спроса на такси и велосипеды
Urban2Vec - мультимодальная модель без учителя, построенная на данных о POIs( дорогах, зданиях, парках, транспортных узлах) и снимков с камер. Создает эмбединги (вектора признаков) для городских районов с целью прогнозирования или сравнения их между собой
CATUS - модель для рекомендации следующей категории POI в районе. Авторы заверяют, что модель может работать на любом городе.
И наконец, Population Dynamics Foundation Model от Google
Идея: Google взял имеющиеся у него данные, а именно данные о поисковых трендах, уровень активности людей и бизнесов, картографической информации и климатических показателях и создал на их основе эмбеддинги ( с помощью GNN) на уровне почтового индекса и округа (country) в США. Основное преимущество GNN в том, что они позволяют учитывать отношения как между различными слоями: например трафиком и климатом, так и между пространственными единицами. Еще одно преимущество, что создание эмбедингов не требует таргета (unsupervised learning), поэтому инструмент получается универсальным - он просто формирует портрет каждой локации, а дальше его можно использовать в любой задаче.
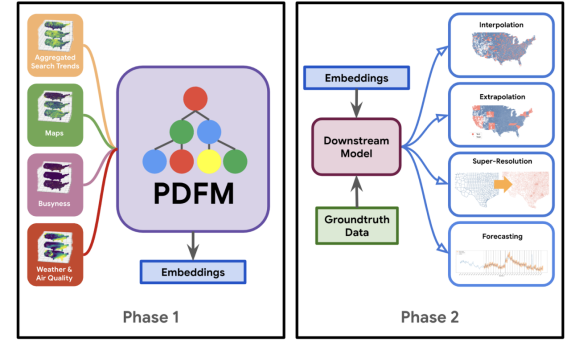
То есть, в отличие от большинства предыдущих моделей, результаты модели Google - это просто набор признаков, который можно использовать внутри вашей модели, чтобы улучшить ее качество. При этом список задач большой: от заполнения пробела в данных, до прогнозирования уровня бедности. Более того авторы проверили эмбединги на 27 кейсах и подтвердили, что во всех случаях результаты стали лучше, чем у классических подходов.
Целиком прочитать статью можно тут
А тут много примеров, как пользоваться embeddings (напомню, что речь про США). Прелесть в том, что хорошо они работают даже с линейной регрессией.
А что для других стран
По идее в статье указано, что возможно использование в других странах, но тут нужно понимать, что это возможно только в том случае, если вы можете собрать такие же признаки как были на входе у google, а это включает в себя данных о поисковых трендах. Так что если вы не работает в Яндексе, можете забыть об этом. И кроме того, используя модель вы предполагаете, что в вашей стране связь между транспортом, экономикой, окружающей средой, плотностью населения и тд такая же, как в США.
Вобщем, если вы вдруг не работаете с США, то модель подойдет скорее для вдохновения, что тоже не плохо:)
P.S. если вы разрабатывали или использовали в задачах Urban Foundation model, напишите - очень интересно. Я в свою очередь обещаю вернуться с собственным примером использования одной из них в ближайшие месяц- два.
Ольга Чудинова
Здравствуйте! Очень интересные модели, большие возможности... Жду с нетерпением пример использования)
Ольга Чудинова
Инна, интересно ваше мнение относительно того, в каких направлениях (областях, задачах) можно всё-таки применить модели, обученные на американских данных, для российской практики?
GeoBrain
Ольга Чудинова, могу ответить только математически: если российские данные похожи на те, что были в обучаемой выборке, то можно применить модель. Дальше решение должно применяться исходя из задачи, например если на открытие магазина в обеих странах влияют доходы населения и поток - чем выше, тем лучше, то модель можно применить. Конечно, всегда нужно валидировать результат