Восстание против меточного шума
В этом открытом длиннопосте поговорим о меточном шуме и о том, как с ним бороться. Код приложен к посту.
В прикладном машинном обучении, особенно в высоконаучных приложениях вроде той же биоинформатики, иногда возникают интересные задачи эпистемиологического характера в духе "А как мы можем понять, что из этих данных вообще можно узнать, и насколько они правильные?".
Предположим, что существует некий датасет (X, y_gathered), где X -- данные, а y_gathered -- метки. (Бусти, втф, добавь латех в редактор!)
Этот датасет был, например, собран людьми, у которых руки растут не из того места -- реальные метки y_real и собранные метки y_gathered отличаются так, что y_gathered = y_real + N, где N -- некий шум неизвестной природы. Также мы можем предположить, что сама метка y_real -- какая-то сложноопределимая хрень, насчет которой спорят эксперты (ТМ) и никак не могут определиться с результатом.
Для нас эти две постановки эквивалентны.
Есть интерес в том, чтобы:
1. Попытаться понять, какие из меток в y_gathered неправильные и соответствующие примеры выкинуть из датасета;
2. Насколько реальный диапазон y_real отличается от диапазона y_gathered, или, если говорить о классификации, насколько классы из y_real соответствуют классам в y_gathered;
3. Какой может быть модель шума -- какие классы проще всего между собой перепутать?
В общем виде этим заннимается теория уверенного обучения (confident learning), которая предлагает свою формализацию понятия меточного шума и общие подходы к этим вопросам. Сегодня мы попробуем поиграться с решением задачи 1, и посмотреть на примере, а можно ли тем же самым подходом решить задачу 2. Про задачу 3 поговорим как-нибудь в другой раз.
Давайте попробуем воспроизвести алгоритм Repeated Cross-Validations (ReCoV) из статьи https://arxiv.org/pdf/2306.13990 -- он достаточно прост для иллюстрации уверенного обучения и в целом прикольный для практического применения.
Потренируемся мы даже не на кошках, а на ирисах -- классическом наборе данных. В качестве модели возьмем логистическую регрессию.
Предварительно надо будет ирисы загадить. Сделаем мы это несколькими способами:
1. В M из примеров мы перепутаем метки;
2. L от одного из классов будет отдано в новый несуществующий класс peniscaninica;
3. L, M, K от трех реальных классов будет отдано в новый несуществующий класс peniscaninica;

Интересно посмотреть, получится ли с помощью метода ReCoV выловить все неправильные метки и понять, что один из четырех классов -- выдумка прогрева ради.
Сначала разобъем по классике и обучим просто модель:

Данные выглядят вот так теперь (если делать PCA):

Видно, что в сценарии 1 у нас все классы немного смешались, а в сценариях 2 и 3 появились новые точки странно определенного класса peniscanininca.
Модель, которую будем использовать, -- логистическая регрессия.

Посмотрим производительность:

Как мы видим, довольно точные предсказания. Что же получается, если метки испорчены?
У нас сразу получаются проблемы со сходимостью... Совпадение? Не думаю.

Срааазу все стало плоховатенько, ну кто бы мог подумать?;) Наблюдаем проблемы с точностью на испорченных метках.

Для сценария 1 есть какие-то смешные ошибочные предсказания.

Для сценария 2, вся peniscaninica была совершенно справедливо предсказана как versicolor.

Для сценария 3 часть peniscaninica была предсказана как setosa, а часть как versicolor.
Давайте попробуем сделать 5-фолдовую кросс-валидацию на тренировочных данных, чтобы было с чем сравнивать перформанс на настоящих, испорченных и очищенных метках:
На настоящих:

На испорченных:

Запомним эти значения и идем дальше.
Алгоритм ReCoV предлагает нам сделать большое количество кросс-валидаций и сохранять плохие фолды в память -- ошибочные айдишники будут систематически попадать в плохие фолды с ростом количества запусков. В зависимости от порога по количеству попаданий в плохие фолды, можно отличить ошибочные айдишники от правильных, попавших в плохие фолды случайно.
У ReCoV есть два гиперпараметра -- N, количество запусков и k, количество фолдов кросс-валидации. Начинаме мы с генерации N сидов для запусков обучения. Для каждого сида мы разделяем тренировочные данные на k фолдов, обучаем k моделей на тренировочных фолдах и проверяем на тестовых. Худший тестовый фолд скопом добавляем в список кандидатов. После завершения всех запусков, объявляем ошибочными все примеры, которые встречаются в списке кандидатов чаще порогового значения.

Сначала уберем ворнинги, ибо не интересно уже:

Давайте посмотрим на распределения попаданий. Теорема из статьи говорит нам, что на большом количестве кросс-валидаций количество попаданий испорченных меток в плохой фолд и количество попаданий чистых меток в плохой фолд будут разделяться между собой, потому что фолды с большим количеством чуши будут предсказываться хуже.

В целом да, похоже, везде мы наблюдаем что-то в духе бимодального или многомодального распределения. На самом деле, для каждого плохого фолда мы наблюдаем гипергеометрическое распределение -- вероятность того, что в выборке из n объектов ровно k являются бракованными. А в сумме для всех фолдов нам удобно использовать модель смесей гауссиан для определения порога сепарации между испорченными и чистыми примерами или найти порог тупо глазами лол. В статье рекомендуют оба варианта в зависимости от ситуации. В целом может помочь любой алгоритм кластеризации, хоть k-means. Попробуем:
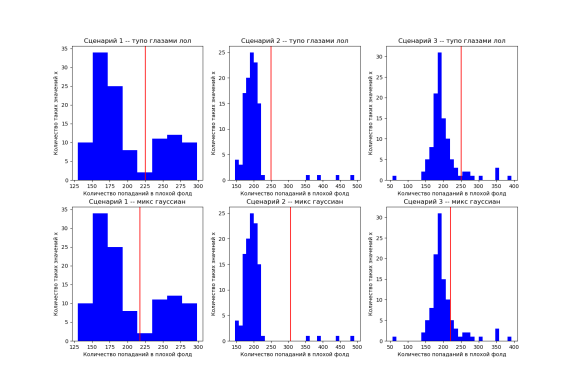
Как видите, в целом один хрен. Ну для наших данных по крайней мере.
Давайте посмотрим, как хорошо мы определили плохие образцы для каждого сценария. Для этого будем новучными и используем меру Жаккара, она же Intersection over Union (IoU). Тут идет немного моя отсебятина, потому что в статье таким способом производительность алгоритма не оценивали.

Видим забавные вещи. Во-первых, установка порога тупо глазами сработала немного лучше, чем смесь гауссиан. Наверное, у меня просто хороший глазомер;)
Во-вторых, по какой-то причине, для сценариев 2 и 3 результаты какие-то совсем плохие.
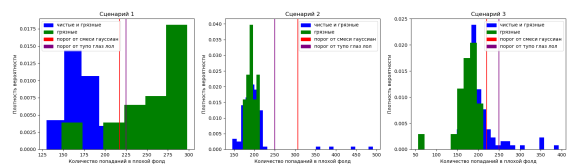
Для сценария 1 все понятно -- большую часть шума мы выловили.
Сценарий 2 и сценарий 3 же показывают, что по количеству попаданий в плохой фолд испорченные и чистые данные отличаются очень плохо.
Почему? Не знаю. Возможно, дело в количестве данных, во влиянии k и N, или чего-то еще. Мне лично кажется, что метода ReCoV недостаточно для хорошего определения того, что у тебя есть целый фальшивый класс в данных. Для этого нужны какие-то дополнительные подходы. Поскольку я сейчас только начинаю погружаться в вопрос уверенного обучения, я пока не знаю, какой. Мое впечатление на текущий момент состоит в том, что задача обнаружения соответствия классов и задача восстановления зашумливающего процесса сильно связаны.
Давайте теперь вернемся к пятифолдовой кросс-валидации и посчитаем результаты для очищенных данных:

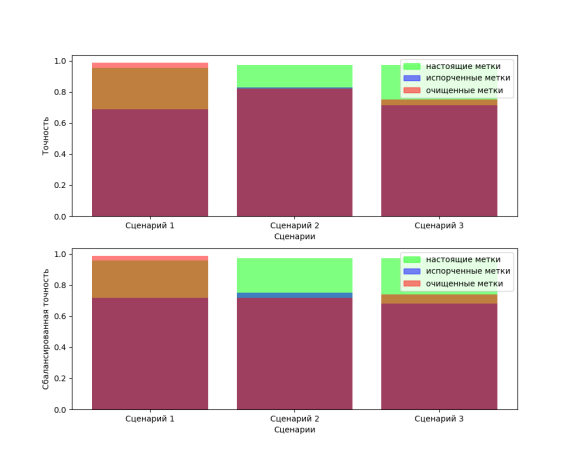
Видим, что для сценария 1 у нас перформанс лучше, чем на настоящих метках, что ожидаемо -- меньше значений дает больший вес каждого правильного ответа. Для сценария 2 перформанс почти не отличается, только для грязных немного лучше, чем на очищенных, для сценария 3 перформанс на очищенных лучше, чем на грязных. В целом понятно, что для определения наличия фальшивого класса метод ReCoV не подходит. По крайней мере на этих данных.
В той же статье авторы ReCoV предложили еще быстрый алгоритм fastReCoV, который отличается хитрой оценкой вероятности попадания в плохой фолд. Его мы рассмотрим в продолжении, которое будет после второй части истории об индуктивном конформном предсказании. Мяу!
ipynb
ReCoV.ipynb427.31 Kb
длиннопост
машинное обучение
А М
Хороший пост! Интересно было почитать. Изложенное нужно будет опробовать на своих данных)
Nov 12 2024 08:56 
1




