Как запустить локальную модель (например, Gemma 4 26B A4B) на своём ПК и подключить её к LiterAI через API LM Studio

Вы можете запустить мощную
языковую модель прямо на своём компьютере и подключить её к любимому сайту для ролевых историй.
В этом посте покажем инструкцию как это сделать.
языковую модель прямо на своём компьютере и подключить её к любимому сайту для ролевых историй.
В этом посте покажем инструкцию как это сделать.

Шаг 1: Установка и запуск LM Studio
LM Studio — это бесплатное приложение с графическим интерфейсом для запуска нейросетей прямо на вашем компьютере с Windows, macOS или Linux. Оно не требует знаний программирования и сложной настройки окружения.
- Скачайте и установите LM Studio с официального сайта lmstudio.ai.
- Слева в меню выберите пункт - поиск моделей. Откроется окно с поиском. Там вбейте название G4-MeroMero-26B-A4B. Справа в окне появится описание модели, там выберите G4-MeroMero-26B-A4B-IQ4_XS.gguf и загрузите (скачайте) ее.

Модель G4-MeroMero-26B-A4B - это до-тренированная на большом дата сете модель Gemma 4 26B A4B и оптимизированная под домашние ПК. Модель может работать и на видеокарте и на оперативной памяти ПК.
Почему Gemma 4 26B A4B — идеальный выбор для РП?
Gemma 4 сочетает Dense- и Mixture-of-Experts (MoE) архитектуры и хорошо подходит для задач генерации текста, кодинга и рассуждений.
Но главное для ролевых историй — это скорость и качество. Буква «A» в названии 26B A4B означает «активные параметры»: модель задействует лишь 4B из 26B параметров при каждом обращении, что делает её значительно быстрее, чем можно предположить по общему объёму. По скорости инференса она сопоставима с 4B-моделью. Gemma 4 обеспечивает более «человеческий» подход в творческом письме и ролевых сценариях. Контекстное окно модели составляет до 256K токенов — это позволяет вести длинные многоглавные РП-истории без потери контекста. Для локального использования квантизованные версии нативно запускаются на потребительских GPU. Эта модель активирует только 4B параметров из 26B, что делает её удивительно быстрой на потребительском железе, даже на MacBook без дискретного GPU.
Шаг 2: Активация локального API-сервера
Чтобы literai.ru мог общаться с вашей моделью, нужно превратить LM Studio в HTTP-сервер.
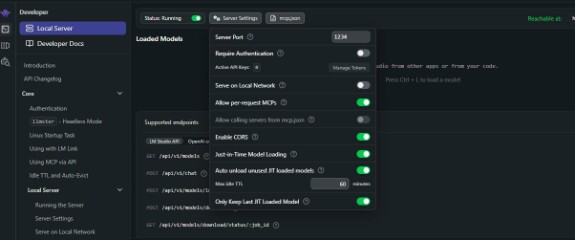
Шаг 3: Загрузка модели и подключение API-сервера
Чтобы literai.ru мог общаться с вашей моделью, нужно превратить LM Studio в HTTP-сервер. Для начала загрузите модель (необходимо загрузить модель в память). В левом меню в LM Studio нажмите первый пунк, откроется окно с запуском чата. Сверху кнопка - Load,
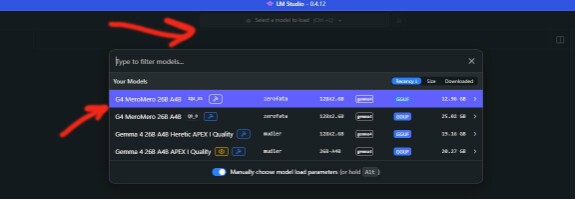
Выберите модель, нажмите загрузить. Появится окно с параметрами загрузки модели. Жмем загрузить. Требуется некоторое время пока модель загрузится в память.

Шаг 4: Добавляем API на сайт Literai.ru и запускаем чат
Переходим на сайт https://literai.ru кликаем на шестеренку в правом верхнем углу, выбираем подраздел - Провайдеры, жмем кнопку - добавить новый.
Вбиваем такие данные:
Название модели - любое на ваш вкус (g4-meromero-26b-a4b)
Модель: g4-meromero-26b-a4b@iq4_xs
API Key: любой, можно написать 12345
И делаем этот провайдер активным (кнопка On)

Нажмите кнопку "Проверить соединение", в браузере появится всплывающее окошко с запросом разрешить передавать сайту данные. Жмите ок. Это проверка браузера на безопасность, чтобы приложение LMStudio отправлять данные на во вкладку с сайтом.
Все, готово.
После этого можно запускать любые чаты и модель будет работать локально на вашем компьютере, даже без интернета.
Если у вас есть видеокарты с памятью от 8гб, то вы можете дополнительно установить еще одну модель
gemma-4-26B-A4B-it-APEX-GGUF которая показывает отличные результаты в работе.
gemma-4-26B-A4B-it-APEX-GGUF которая показывает отличные результаты в работе.